Databricks Workspace
The Databricks Workspace connector enables you to interact with your Databricks workspace programmatically, allowing you to manage clusters, execute queries, and work with your data assets.
Pre-requisites
Before setting up the connector, ensure you have:
- A Databricks workspace with appropriate permissions
- Access to create Service Principals in your Databricks workspace
- Administrative privileges to grant permissions to the Service Principal
Step 1: Setting up Authentication
1.1 Create a Service Principal
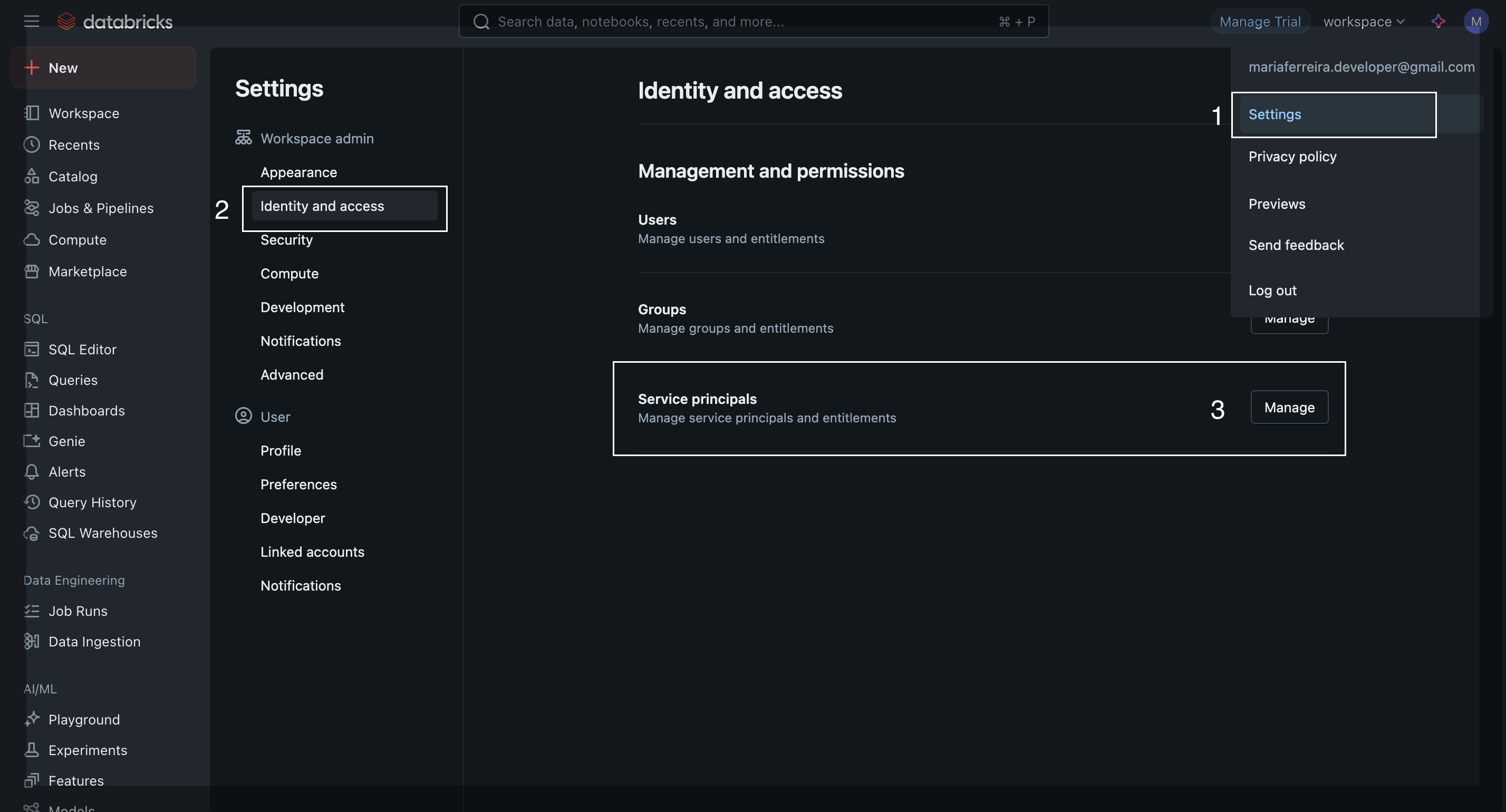
- Navigate to your Databricks workspace:
https://[YOUR_INSTANCE_URL].cloud.databricks.com - Go to Settings → Identity and Access → Service Principals
- Click Add Service Principal and provide a name (e.g., "Abstra Integration")
- After creation, select your newly created Service Principal
1.2 Generate Client Credentials
- In the Service Principal details, navigate to the Secrets tab
- Click Generate Secret to create your client ID and secret
- Important: Save these credentials securely as they won't be shown again
1.3 Configure the Connection in Abstra
- Open your Abstra Console and select the
- Navigate to Connectors and select Databricks Workspace
- Provide the following credentials:
- Instance URL: Your Databricks workspace URL (e.g.,
https://[YOUR_INSTANCE_URL].cloud.databricks.com) - Client ID: The client ID from your Service Principal
- Client Secret: The client secret from your Service Principal
- Instance URL: Your Databricks workspace URL (e.g.,
Step 2: Configuring Permissions
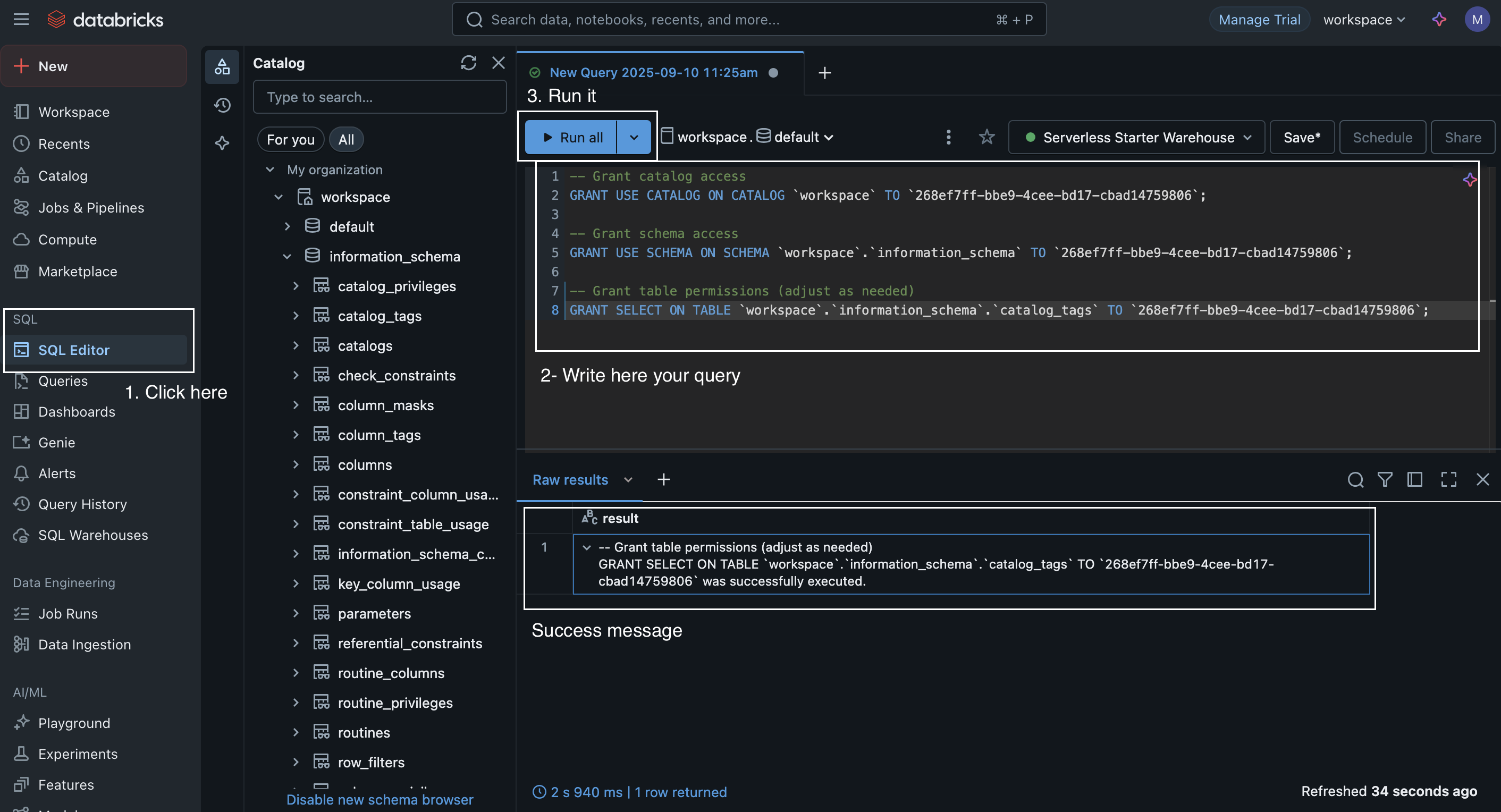
Your Service Principal needs appropriate permissions to access Databricks resources. The required permissions depend on your use case. You can grant access at different levels: entire catalog, specific schema, or individual tables. Execute the following SQL queries in your Databricks workspace:
For Data Access (Unity Catalog)
-- Grant catalog access
GRANT USE CATALOG ON CATALOG `<YOUR_CATALOG_NAME>` TO `<SERVICE_PRINCIPAL_APPLICATION_ID>`;
-- Grant schema access
GRANT USE SCHEMA ON SCHEMA `<YOUR_CATALOG_NAME>`.`<YOUR_SCHEMA_NAME>` TO `<SERVICE_PRINCIPAL_APPLICATION_ID>`;
-- Grant table permissions
GRANT SELECT ON TABLE `<YOUR_CATALOG_NAME>`.`<YOUR_SCHEMA_NAME>`.`<YOUR_TABLE_NAME>` TO `<SERVICE_PRINCIPAL_APPLICATION_ID>`;
For Cluster Management
- Assign the Service Principal to appropriate workspace groups
- Grant cluster creation/management permissions through workspace admin settings
Step 3: Using the Connector in your workflow
Abstra offers two approaches to integrate Databricks functionality into your workflows:
For a complete list of available actions and their parameters, visit Databricks Workspace Actions.
Option A: AI-Assisted Development
You can use natural language prompts with Abstra's AI to generate Databricks operations. Here are some example prompts:
Query Data:
Select the first 10 rows from table "customers" in catalog "sales_data" and schema "production" using the databricks-workspace connector
Cluster Management:
List all active clusters in my Databricks workspace using the databricks-workspace connector
Job Operations:
Create a new job that runs daily at 9 AM to process data from the "raw_data" table using the databricks-workspace connector
If you encounter permission errors, verify that your Service Principal has the necessary grants. Common issues include:
- Missing catalog/schema access: Ensure you've granted USE CATALOG and USE SCHEMA permissions
- Insufficient table permissions: Grant appropriate permissions (SELECT, INSERT, UPDATE, DELETE) based on your operations
- Cluster access: Verify the Service Principal can access or create clusters for job execution
Use the SQL commands in Step 2 to resolve permission issues.
Option B: Manual Python Development
For developers who prefer direct control, you can use Python code to interact with Databricks through the connector API from your Abstra Editor:
Example 1: Query Data
# Execute a SQL query
from abstra.connectors import run_connection_action
connection_name = "databricks-workspace"
action_name = "post_api_2.0_sql_statements"
params = {
"statement": "SELECT * FROM sales_data.production.customers LIMIT 10",
"warehouse_id": "your_warehouse_id", # specify warehouse
"catalog": "workspace",
"schema": "information_schema",
"wait_timeout": "30s",
"format": "JSON_ARRAY",
"disposition": "INLINE"
}
result = run_connection_action(connection_name, action_name, params)
print("Query results:")
print(result)
Example 2: List Clusters
# Get all clusters
from abstra.connectors import run_connection_action
connection_name = "databricks-workspace"
action_name = "get_api_2.1_clusters_list"
params = {}
clusters = run_connection_action(connection_name, action_name, params)
print("Available clusters:")
print(clusters)
Troubleshooting
Connection Issues:
- Verify your instance URL format (should include https://)
- Check that your Service Principal credentials are correct
- Ensure your workspace allows API access
Permission Errors:
- Review the SQL grant statements in Step 2
- Verify Service Principal has appropriate workspace roles
- Check Unity Catalog permissions if using Unity Catalog tables
Query Failures:
- Ensure the specified warehouse/cluster is running
- Verify table and column names exist
- Check SQL syntax for Databricks compatibility